
728x90
1. 데이터 프레임 생성
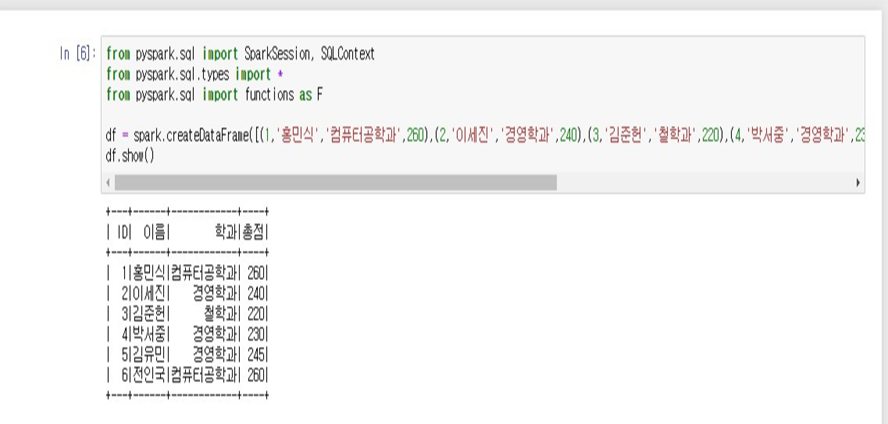
- df = spark.createDataFrame([1,'홍민식', '컴퓨터공학과', 260), (2, '이세진', '경영학과', 240), (3, '김준헌', '철학과', 220), (4, '박서중', '경영학과', 230), (5, '김유민', '경영학과' 245), (6, '전인국', '컴퓨터공학과', 260)],['ID', '이름', '학과', '총점'])
- df.show()
2. 레코드 삽입
- df1 = spark.createDataFrame([(7, '하상오', '컴퓨터공학과', 270), (8, '박선아', '컴퓨터공학과', 250)])
- 새 데이터 프레임을 생성한 후,
- df2 = df.union(df1)
- 두 프레임을 결합한 새로운 데이터 프레임 생성
- df2.show()

3. 평균 열 삽입 1
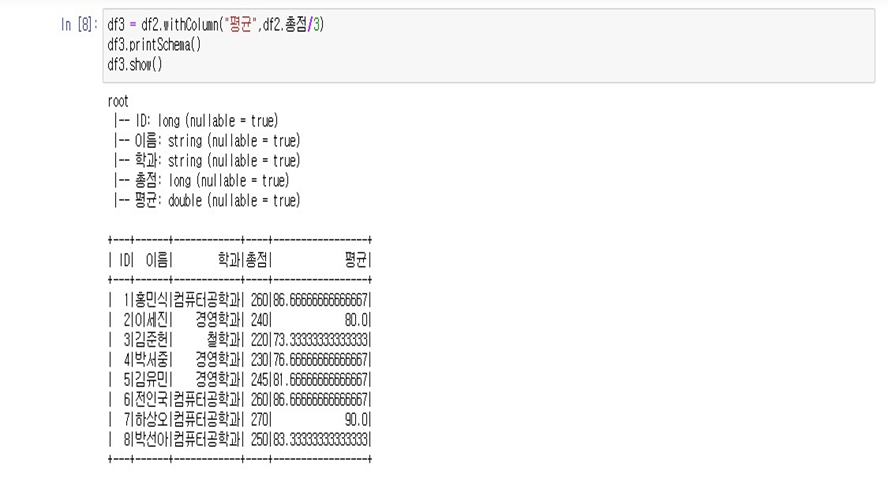
- df3 = df2.withColumn("평균", df2.총점/3)
- df3.printSchema()
- df3.show()
4. 평균 열 삽입2, 소수점 이하 2자리 반올림
- from pyspark.sql.functions import round
- df4 = df3.withColumn("평균", round(df3.평균,2))
- df4.show()

5. 총점 열 제거
- df5 = df4.drop('총점').show()

6. 질의 연산
- #select() 연산
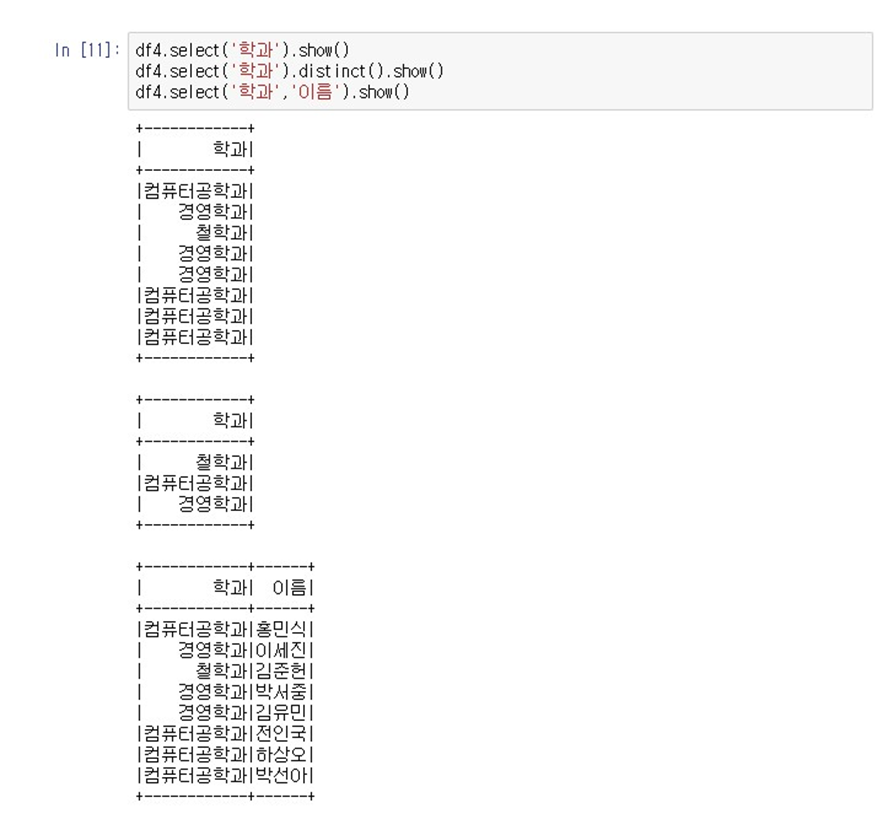
- df4.select('학과').show()
- df4.select('학과').distinct().show()
- df4.select('학과', '이름').show()
- filter, where 연산
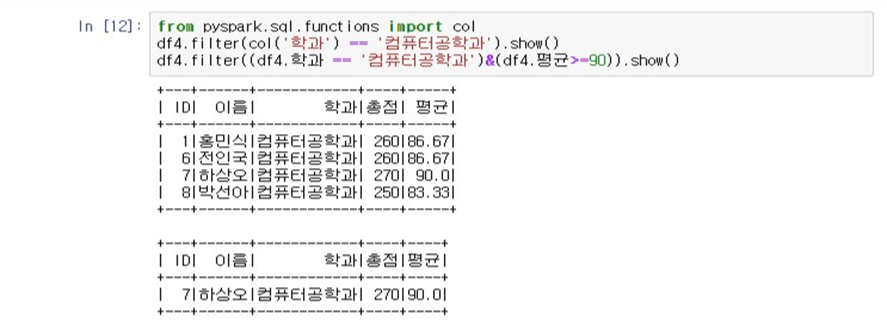
- from pyspark.sql.functions import col
- df4.filter(col('학과') == '컴퓨터공학과').show()
- df4.filter((df4.학과 == '컴퓨터공학과) & (df4.평균 >= 90)).show()
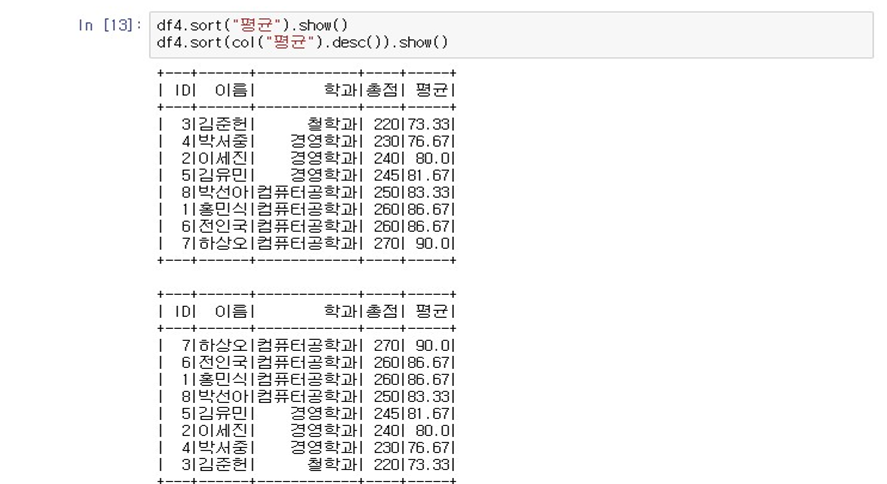
- 정렬 조회
- df4.sort("평균").show()
- df4.sort(col("평균").desc()).show()
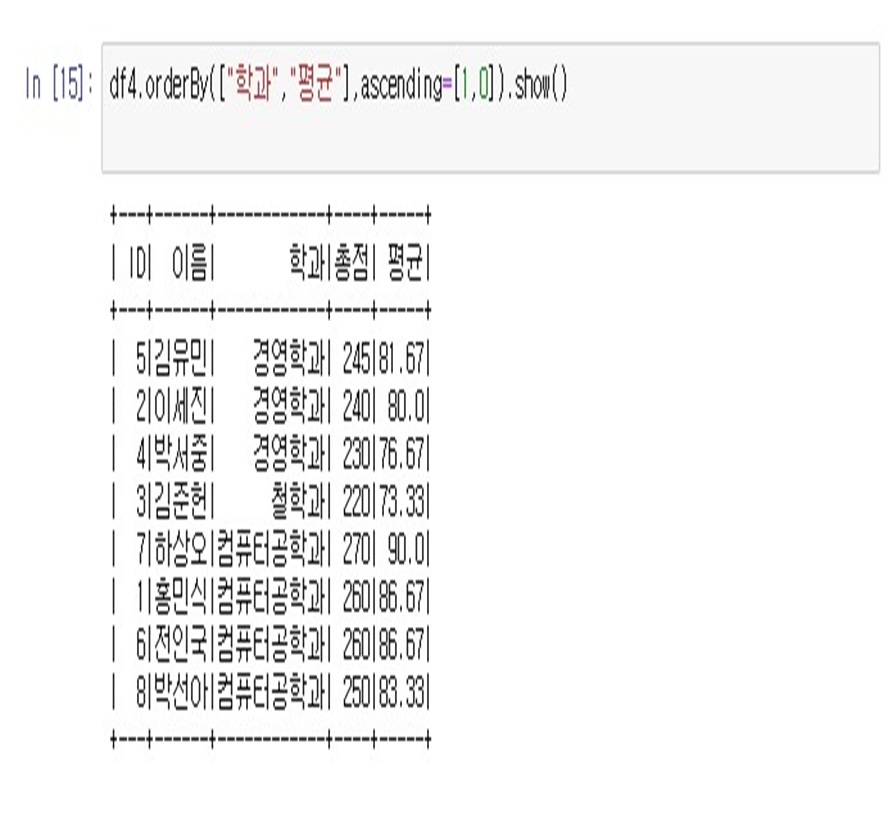
- 학과는 올림차순, 평균은 내림차순 정렬
- df4.orderBy(["학과", "평균"], ascending=[1,0]).show()
728x90
'빅데이터' 카테고리의 다른 글
| 빅데이터 - 7. 단어 카운트 (0) | 2022.10.09 |
|---|---|
| 빅데이터 - 6. SFPD 응용 (0) | 2022.10.09 |
| 빅데이터 - 4. 스파크 설치 및 테스트 (0) | 2022.08.30 |
| 빅데이터 - 3. 맵리듀스 응용 구축 (0) | 2022.08.30 |
| 빅데이터 - 2. 하둡 설치 (0) | 2022.08.24 |