
728x90
1. OpenJdk-8 자바 설치
- https://openjdk.java.net/
- sudo apt install -y openjdk-8-jdk
- 자바 환경변수 설정
- ~/.bashrc에 추가
- export JAVA_HOME="usr/lib/jvm/java-8-openjdk-amd64"
- export PATH=$JAVA_HOME/bin:$PATH
- export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH
- $ java -version을 통해 자바 설치 버전 확인
2. 노드 호스트 이름 설정
- /etc/hosts
- 192.168.100.200 master MASTER
- 192.168.101.201 worker1 WORKER1
3. 하둡 설치 - 패키지 다운로드
- wget https://archive.apache.org/dist/hadoop/core/hadoop-3.3.0/hadoop-3.3.0.tar.gz
- 압축해제
- tar -xvzf hadoop-3.3.0.tar.gz
4. 하둡 설정 - 환경 변수
- ~/.bashrc에 추가

- 추가 후 적용
- source ~/.bashrc
5. 하둡 설정 - 데이터 노드 설정
- ~/hadoop-3.3.0/etc/hadoop/workers
- master
- worker1
6. 하둡 설정 - SSH 인증 설정
- 마스터 노드에서 각 노드의 공용키 생성
- $ ssh-keygen -t rsa
- $ ssh worker1 'ssh-keygen -t rsa'
- 각 노드에 생성된 공용 키를 ~/.ssh/authorized_keys에 수집
- $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- $ ssh worker1 'cat ~/.ssh/id_rsa.pub' >> ~/.ssh/authorized_keys
- 마스터에서 수집된 공용 키를 워커 노드로 배포
- $ scp ~/.ssh/authorized_keys worker1 :~/.ssh/authorized_keys
- 테스트 : 암호 입력 요구 없이 접속해야 성공
- $ ssh worker1
7. 하둡 설정 - core-site.xml
- $HADOOP_CONF_DIR/core-site.xml

8. 하둡 설정 - hdfs-site.xml
- $HADOOP_CONF_DIR/hdfs-site.xml

9. 하둡 설정 - yarn-site.xml
- $HADOOP_CONF_DIR/yarn-site.xml


10. 하둡 설정 - mapred-site.xml
- $HADOOP_CONF_DIR/mapred-site.xml

11. 하둡 설정 - hadoop-env.sh
- $HADOOP_CONF_DIR/hadoop-env.sh

12. 하둡 설정 - yarn-env.xml
- $HADOOP_CONF_DIR/yarn-env.sh

13. 워커 노드에 하둡 배포
- 마스터 노드에서 작성하였던, 이전의 설치 및 환경 설정을 워커 노드에 복사하여 배포한다.
- .bashrc 배포
- $ scp /home/bigdata/.bashrc worker1:~
- 하둡 설치 디렉토리 배포
- $ scp -r /home/bigdata/hadoop-3.3.0 worker1 :~
14. 하둡 실행
- 하둡 초기 실행시, HDFS와 YARN 데몬 실행
- 하둡 실행 명령어 : $ $HADOOP_HOME/sbin/start-all.sh
- 하둡 종료 명령어 : $ $HADOOP_HOME/sbin/stop-all.sh
- 첫 실행시 한번 만 마스터에서 네임노드를 포맷
- $ hdfs namenode -format
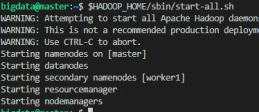
15. 하둡 클러스터 동작 확인
- $ hdfs version

- $ jps


16. 클러스터 동작 확인 - 네임노드 웹
- http://192.168.0.10:9870 접속

17. 하둡 실행 Test - wordcount
- 하둡의 명령 형식
- $hadoop fs -command
- $hdfs dfs -command
- command : ls, cat, cp, mv, put, ...
- $ hadoop fs -ls /
- $ hadoop fs -mkdir /input
- $ hadoop fs -put $HADOOP/README.txt /input
- $ hadoop fs -ls /input
- $ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /input/README.txt/output
- hadoop fs -cat /output/part-r-00000

728x90
'빅데이터' 카테고리의 다른 글
| 빅데이터 - 6. SFPD 응용 (0) | 2022.10.09 |
|---|---|
| 빅데이터 - 5. 스파크 데이터프레임 연산 (0) | 2022.09.18 |
| 빅데이터 - 4. 스파크 설치 및 테스트 (0) | 2022.08.30 |
| 빅데이터 - 3. 맵리듀스 응용 구축 (0) | 2022.08.30 |
| 빅데이터 - 1. 클러스터 서버 환경 구축 (2) | 2022.08.24 |