빅데이터
빅데이터 - 7. 단어 카운트
IT의 큰손
2022. 10. 9. 20:12
728x90
1. 입력 데이터 로컬 파일 복사
- $ hadoop fs -mkdir /sparkdata/wordcnt
- $ hadoop fs -put ~/hadoop3.3.0/*.txt /sparkdata/wordcnt
2. 데이터 적재
- dataDF = sapark.read.text("/sparkdata/wordcnt")
- dataDF.printSchema()
- print("총 레코드(라인)수 = ", dataDF.count())
- dataDF.show(5, truncate=False)

3. 구두점 기호 제거 실행
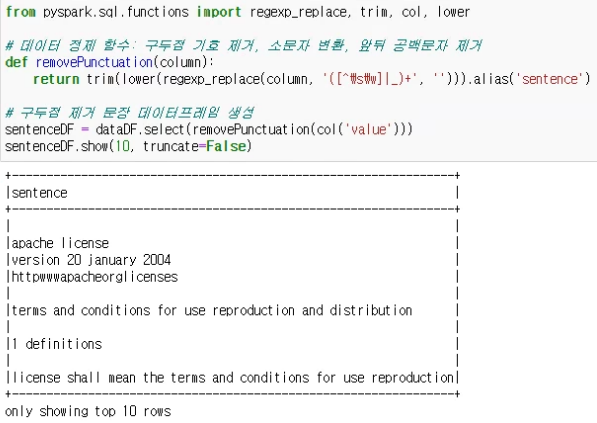
- from pyspark.sql.functions import regexp_replace, trim, col, lower
- #데이터 정제 함수 : 구두점 기호 제거, 소문자 변환, 앞뒤 공백문자 제거
- def removePunctuation(column):
- return trim(lower(regexp_replace(column, '([^\s\w]|_)+',"))).alias('sentence')
- #구두점 제거 문장 데이터프레임 생성
- sentenceDF = dataDF.select(removePunctuation(col('value')))
- sentenceDF.show(5, truncate=False)
4. 단어 분리
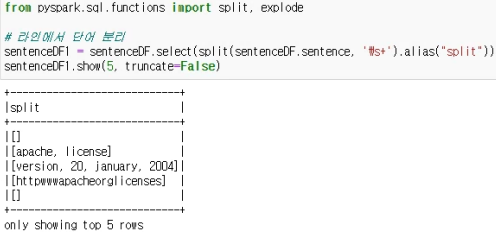
- #라인에서 단어 분리
- sentenceDF1 = sentenceDF.select(split(sentenceDF.sentence, '\s+').alias("split"))
- sentenceDF1.show(5, truncate=False)
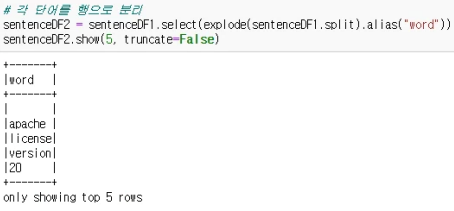
- #각 단어를 행으로 분리
- sentenceDF2 = sentenceDF1.select(explode(sentenceDF1.split).alias("word"))
- sentenceDF2.show(5, truncate=False)
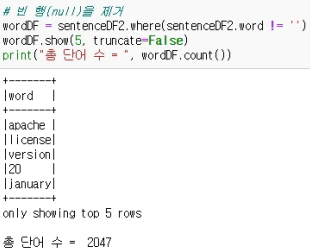
- #빈 행(Null)을 제거
- wordDF = sentenceDF2.where(sentenceDF2.words != ")
- wordDF.show(5, truncate=False)
5. 단어 카운트
- #단어 카운트
- wordDF1 = wordDF.groupby("word").count()
- wordDF1.show(10, truncate=False)

- #단어 카운트, 정렬
- wordDF1.orderBy("count", ascending=0).show(10, truncate=False)

728x90